課題
従来広告の効果測定は、主にCookieやIPを使って以下の様にデータを突合していました。
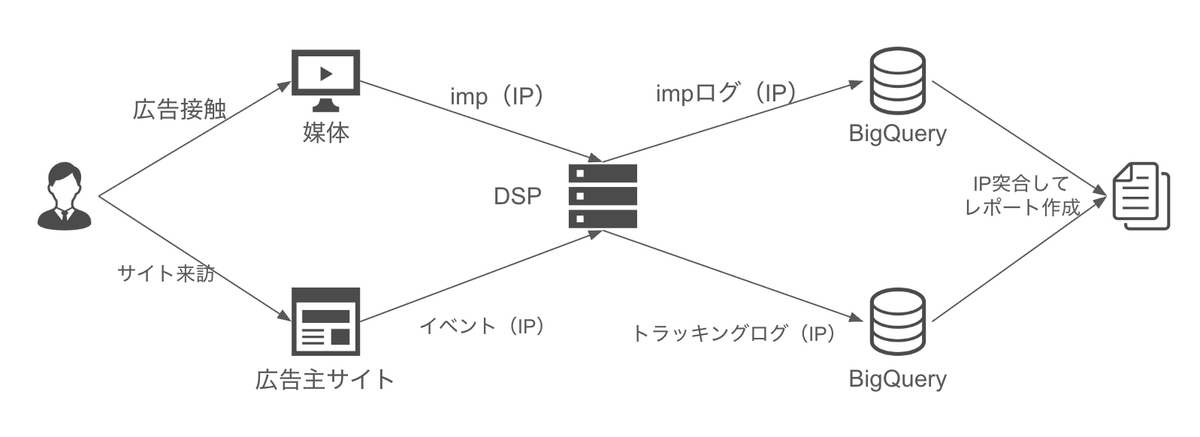
しかしながら最近はプライバシー保護のためGDPRなどによってCookieレスが進んだり、これまでメディア(媒体)から連携されていたIPも連携されないような流れが出てきました。
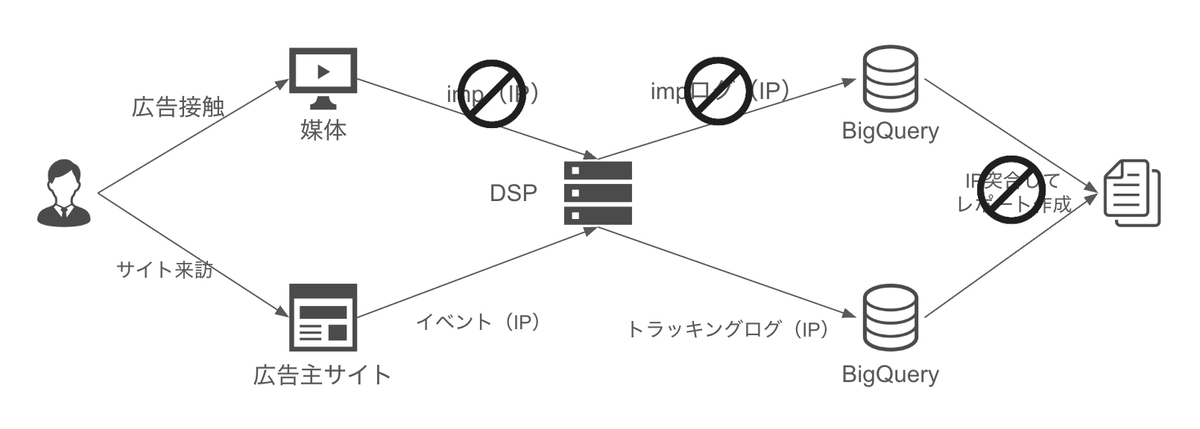
これにより適切な広告効果が計測できない課題が生まれています。
そこでプライバシーを保護しつつ、効果計測もできるようにするソリューションがData Clean Roomです。
続きを読む従来広告の効果測定は、主にCookieやIPを使って以下の様にデータを突合していました。
しかしながら最近はプライバシー保護のためGDPRなどによってCookieレスが進んだり、これまでメディア(媒体)から連携されていたIPも連携されないような流れが出てきました。
これにより適切な広告効果が計測できない課題が生まれています。
そこでプライバシーを保護しつつ、効果計測もできるようにするソリューションがData Clean Roomです。
続きを読むHTTPやgRPCなどのAPIでvalidationを実装する際、次のような課題に直面することがよくあります。
もしProtobufを使ってAPI定義を行っている(スキーマ駆動開発)なら、validationの責務もProtobuf側に寄せてしまうという設計が有効です。
この記事では、そのためのツールである proto-gen-validate を使い、Protobufスキーマでvalidationを定義・自動生成する方法を紹介します。
以前以下の対応を行いましたが、
ツールチップがスクショできないという問題に遭遇しました。 期待する挙動は以下なのですが、
実際はこのようにツールチップが消えてしまいます。
そのため別の方法で実現する必要がありました。
PreparedStatement はSQLを実行する際に「SQL文の構造」と「パラメータ」を分離して扱える仕組みです。
それによって
を図ることが可能です。
今回はその理由を説明します。
例えばMySQLの場合、通常のStatementでは、
SELECT * FROM users WHERE email = 'alice@example.com'; SELECT * FROM users WHERE email = 'bob@example.com';
であるのに対し、PreparedStatementでは次のように使います。
-- 1. 準備 (Prepare) PREPARE stmt FROM 'SELECT * FROM users WHERE email = ?'; -- 2. パラメータをセットして実行 SET @email = 'alice@example.com'; EXECUTE stmt USING @email; SET @email = 'bob@example.com'; EXECUTE stmt USING @email; -- 3. 不要になったら解放 DEALLOCATE PREPARE stmt;
こうすることでどんなメリットがあるかを紹介します。
続きを読むデータベースを扱うと、パフォーマンス向上を考えた際に必ず出てくるコネクションプーリングについてです。
今回はコネクションプーリングの種類とその特徴についてと、各データベースの特性に合わせてどんな選択を取るのが良いかを説明します。
コネクションプーリングのメリットは
です。後述しますが、例えばPostgreSQLは1コネクション=1プロセスモデルであるため、
であった場合、接続プールがなかったとすると 1秒あたり900件のデータベース接続が開閉=毎秒900のプロセスが作成・破棄されるという無駄な処理が発生します。
そこで接続をプール(保持)し、再利用することで無駄を省くのがコネクションプーリングです。
続きを読むで紹介したアーキテクチャの中にBloom Filterというものがありました。
今回はこちらの仕組みを説明します。
Bloom Filterは 偽陽性(無いのにあると回答)はあるが、偽陰性(あるのに無いと回答)はない ことでデータの存在有無をメモリ効率良く保持する確率的データ構造です。
具体的なユースケースとして
などがあります。
前回のLSM Treeは真ん中の分散システムでの存在チェックですね。
続きを読むLSMツリーを理解しやすくするためにアーキテクチャ、Write/Readフロー、コンパクションなどを図解します。
LSMツリー(Log-Structured Merge Tree)は、データベースやストレージで大量の書き込みを高速に処理するための仕組みです。
全体のアーキテクチャはこのようになっています。
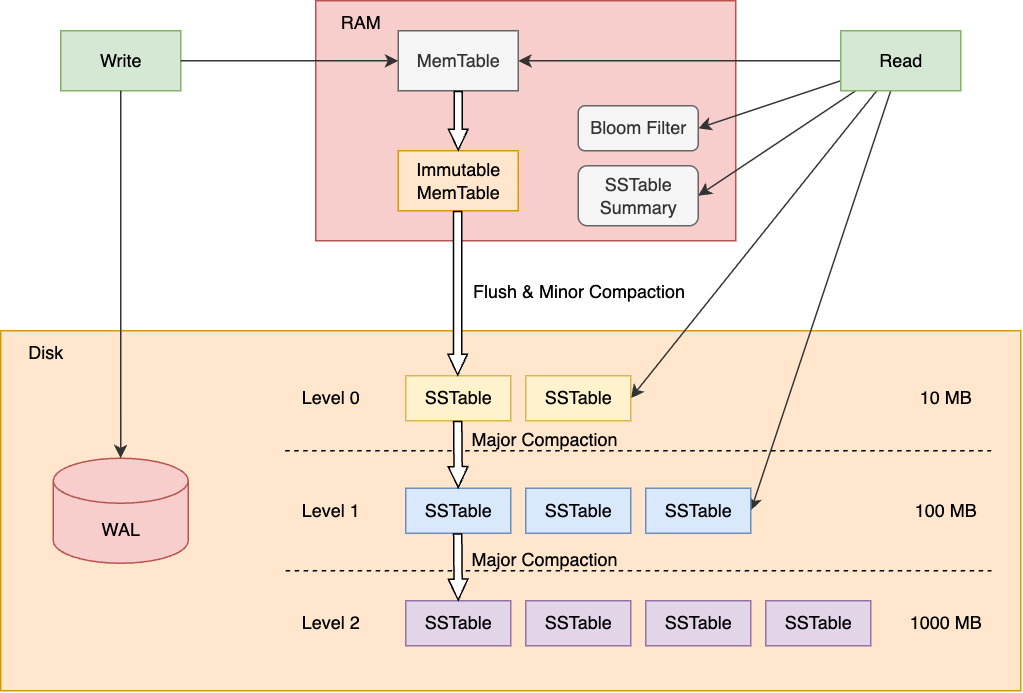
新しいデータはまずメモリにある一時領域(MemTable)に書き込み、同時にログ(WAL)に追記して安全に保存します。 メモリが一杯になると、まとめてディスク上のソート済みファイル(SSTable)に書き出し、古いファイルと統合(コンパクション)して整理します。
続きを読む