概要
Goのポインタを図で理解することで
- ダブルポインタとは
- Goは全て値渡し
- ポインタレシーバと値レシーバの違い
がどういうことかを理解でき、参照渡しの時に
x = y
だと更新されず
*x = *y
だと更新される理由が分かります。
ポインタを図示する
ポインタはメモリアドレスを指すというは理解しているでしょうが、ポインタ変数との関係を分かりやすくするために図示します。
func main() { var x = 100 fmt.Println("x address:\t", &x) var y *int fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) y = &x fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) }
結果
当然ではありますがポインタ変数自体にも異なるアドレスがあります。
x address: 0xc000100010 y value: <nil> y address: 0xc000102020 y value: 0xc000100010 y address: 0xc000102020
図示
先程のコードを図示するとこういう状態です。

代入をすることでこのような状態になります。
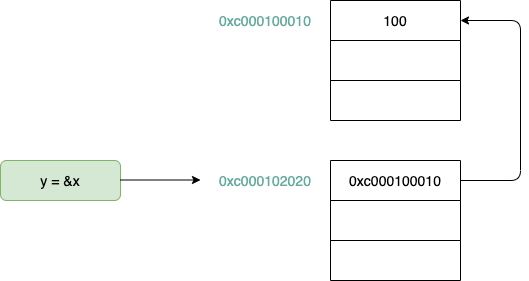
ポインタ変数のyはxのアドレスを値として保持しているわけです。
型としての*と変数の演算子としての*, &
ポインタを考える上で*や&が出てきますが、まず以下のように区別しましょう
- 型としての
* - 変数の演算子としての
*、&
1. 型としての*
型に*をつけることでポインタ変数として定義できます。
ポインタ変数はメモリ上のアドレスを値として入れられる変数です。
なのでその変数の中身はメモリアドレスです。
2. 変数の演算子としての*、&
変数の演算子として
| 演算子 | 何を返すか |
|---|---|
* |
ポインタ変数の指すメモリアドレスの実データdereferencingやindirectingと呼ばれる |
& |
変数がメモリ上で確保された際のアドレス |
を返します。
このことから分かるように、
- ポインタ変数でない
- ポインタ変数だけどnil
の場合に、その変数に*を使うとinvalid indirect ofやinvalid memory address or nil pointer dereferenceが発生します。
ポインタ変数でない
ポインタ変数でないのにポインタ変数用の演算子を使おうとしており、構文的に間違っているのでビルド時にコンパイルエラーとして分かります。
func main() { var x = 100 fmt.Println("x value:\t", *x) }
./prog.go:9:28: invalid indirect of x (type int)
ポインタ変数だけどnil
ポインタ変数が参照するメモリアドレスを保持していないのでpanicが起きます。
ポインタ変数の中身にメモリアドレスが入っているかは動かしてみないと分からないため、コンパイルエラーでなくruntimeエラーになります。
func main() { var x *int fmt.Println("x value:\t", *x) }
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x4990a3]
goroutine 1 [running]:
main.main()
/tmp/sandbox413165628/prog.go:9 +0x23
ダブルポインタはどういう状態か
**intといったダブルポインタがどういう状態かを見てみましょう。
func main() { var x = 100 fmt.Println("x address:\t", &x) var y *int fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) y = &x fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) var z **int fmt.Println("z value:\t", z) fmt.Println("z address:\t", &z) z = &y fmt.Println("z value:\t", z) fmt.Println("z address:\t", &z) }
結果
x address: 0xc00002c008 y value: <nil> y address: 0xc00000e030 y value: 0xc00002c008 y address: 0xc00000e030 z value: <nil> z address: 0xc00000e038 z value: 0xc00000e030 z address: 0xc00000e038
図示
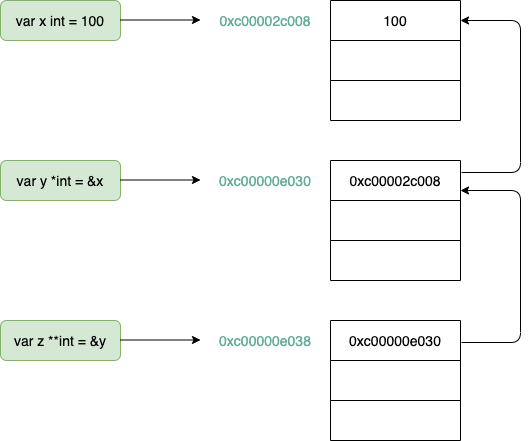
図示するとこういう状態です。
ダブルポインタのzはyのアドレスを値として保持しているわけです。
Goは全て値渡し
ポインタで関係してくるのが参照渡しという概念ですが、以下の通りGoは全て値渡しです。
As in all languages in the C family, everything in Go is passed by value. That is, a function always gets a copy of the thing being passed, as if there were an assignment statement assigning the value to the parameter. For instance, passing an int value to a function makes a copy of the int, and passing a pointer value makes a copy of the pointer, but not the data it points to. (See a later section for a discussion of how this affects method receivers.)
Frequently Asked Questions (FAQ) - The Go Programming Language
では参照渡しはどういう状態かというと、ポインタ変数の値渡し(=コピー)です。
ポインタ変数の値渡しとは
具体的なコードで説明します。
以下のように引数にポインタ変数を渡し、関数内のポインタ変数の値、アドレスを表示してみます。
func main() { var x = "alice" fmt.Println("x address:\t", &x) y := &x fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) show(y) } func show(s *string) { fmt.Println("s value:\t", s) fmt.Println("s address:\t", &s) }
すると引数で渡した変数yと渡された関数内の変数sは参照先が同じではありますが、変数自体は別アドレスである(=コピーされたもの)ことが分かります。
x address: 0xc00010a040 y value: 0xc00010a040 y address: 0xc000102020 s value: 0xc00010a040 s address: 0xc000102028
コピーなのでshow()を呼び出す度にポインタ変数sのアドレスは異なることも確認できます。
図示
図示するとこの状態です。

参照渡しなのに上書きがうまく行かないケース
なので例えば以下のようなコードだと、コピーされたポインタ変数の参照先を変えるだけで、中身のデータを変えていないため上書きしたつもりができていない、ということになります。
func main() { var x = "alice" fmt.Println("x address:\t", &x) y := &x fmt.Println("y value:\t", y) fmt.Println("y address:\t", &y) show(y) fmt.Println(*y) // bobのつもりがaliceのまま } func show(s *string) { tmp := "bob" fmt.Println("tmp address:\t", &tmp) fmt.Println("s value:\t", s) fmt.Println("s address:\t", &s) s = &tmp // 上書きのつもり fmt.Println("s value:\t", s) fmt.Println("s address:\t", &s) }
図示

したがって*で参照先のデータを操作する必要があるわけです。
s = &tmp ではなく *s = tmp
レシーバは単なる関数の第一引数と考える
↓の公式ドキュメントで説明されていますが、メソッド定義は本質的には関数定義と等価です。
https://golang.org/ref/spec#Method_expressions
そしてメソッドのレシーバは第一引数と考えて差し支えないです。
例えば
type Person struct { Name string Age int }
というstructに対して値レシーバとポインタレシーバを用意した場合を考えます。
値レシーバの場合
func (p Person) Greet(msg string) { }
は
func(p Person, msg string) { }
と等価です。
レシーバの値を変更するには?
Personは値のコピーなので元の値を変更することはできません。
func main() { x := Person{"alice", 20} fmt.Printf("x address:\t%p\n", &x) // 0xc00000c0a0 x.Greet("test") } func (p Person) Greet(msg string) { fmt.Printf("p address:\t%p\n", &p) // 0xc00000c0c0 }
図示すると

この状態なので、p側でx側の値を変更することはできません。
ポインタレシーバの場合
func (p *Person) Greet(msg string) { }
は
func(p *Person, msg string) { }
と等価です。
レシーバの値を変更するには?
ポインタ変数を引数にしているので変更可能です。
func main() { x := &Person{"alice", 20} fmt.Printf("x value:\t%p\n", x) // 0xc00000c0a0 fmt.Printf("x address:\t%p\n", &x) // 0xc00000e028 x.Greet("test") } func (p *Person) Greet(msg string) { fmt.Printf("p value:\t%p\n", p) // 0xc00000c0a0 fmt.Printf("p address:\t%p\n", &p) // 0xc00000e038 }
を図示すると

という状態です。
フィールドに対するアクセスは参照先のデータを更新するは既知ですが、全体を更新したい場合は先ほどと同様に
p = &tmp ではなく *p = tmp
と、ポインタ変数を上書きするのではなく、参照先を上書きする必要があります。
まとめ
ポインタ周りを図示することで、一見分かりにくい参照渡しの挙動も理解できるようになります。