Consistent Hashingとは
Consistent Hashingはハッシュテーブルアルゴリズムの1つです。
ハッシュテーブルのサイズの変更をしても柔軟にマッピングできるため、ノードの追加・削除が発生する分散データベースやキャッシュの保存先を決定するといった用途に使われます。
アルゴリズムの説明
ハッシュ化
例えば入力値を0~99の値に変換するハッシュ関数を用意します。
ノードのIDをそのハッシュ関数で変換すると以下のように配置されたとします。

次にデータも同じようにハッシュ関数で変換し、以下のように配置されたとします。

マッピング
データのハッシュ値と同じorより大きな値の中で最も近いノードにマッピングします。
自分よりも大きなハッシュ値を持つノードが存在しない場合は、最小のハッシュ値のノードにマッピングします。

これがConsistent Hashingです。
ノードの追加・削除
Consistent Hashingの特徴としてノードが増減しても柔軟にマッピングできる点です。
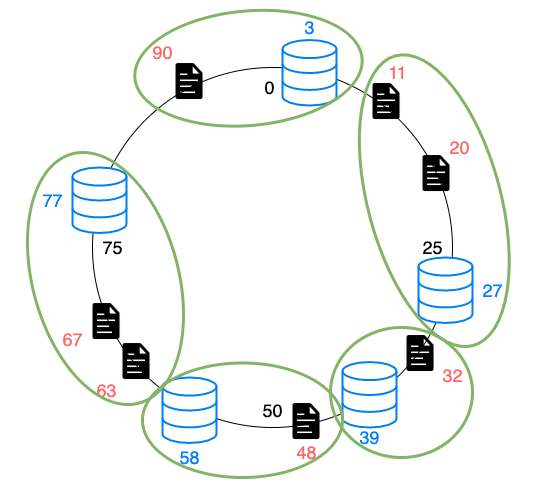
追加
スケールアウトしたくなりノードを追加した場合、

同じルールのままドキュメントが再マッピングできます。
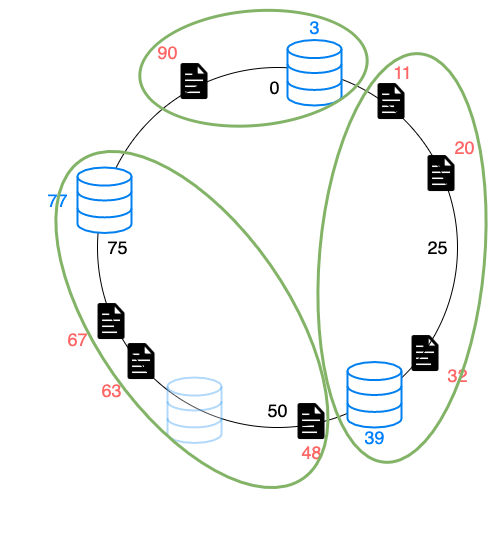
削除
逆に削除された場合も、

同じルールのままドキュメントが再マッピングできます。
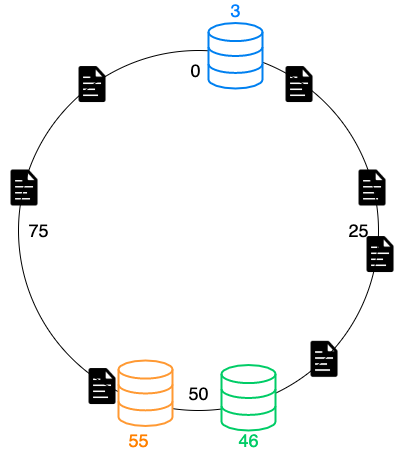
仮想ノード
課題としてノードをハッシュ化した際に偏りが発生する点です。

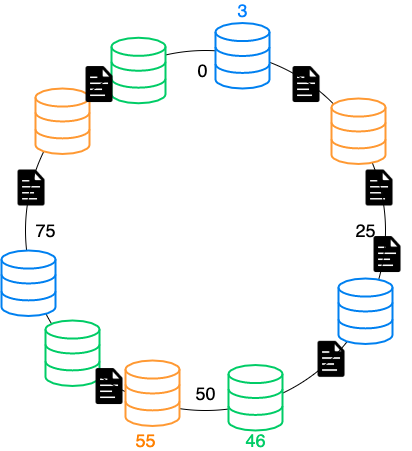
この配置だと3、46のノードにデータが集まりやすく、55のノードにはデータが入りづらく分散されません。
そこでノードIDに+αしてハッシュ化し、仮想的にノードを増やしてデータが分散されやすくします。
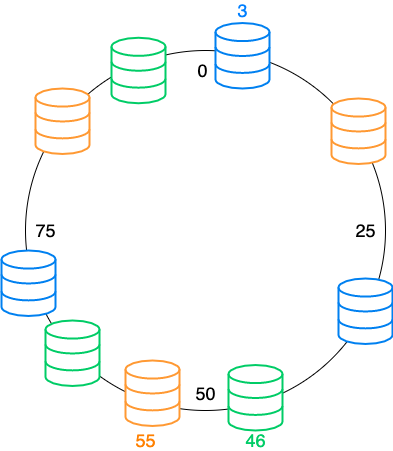
先程のデータも偏りが解消されました。
Pros/Cons
Consistent Hashingのメリット・デメリットは以下です。
Pros
- データを分散して管理できる(負荷分散できる)
- ノードの増減に対しても柔軟に再マッピングできる
- 仮想ノードによって均等に管理できる
- Nノードに対してデータ追加・削除の計算量は
O(log(N))なので、ノードが増えても計算量が爆増すると言ったことがない
Cons
- 各ノードの状態を把握する必要がある
- ノードが落ちていたらデータを書き込まないように
- ノードが死んだ場合の可用性を考慮する必要がある
- もしくはキャッシュ用途としてデータの欠損を許容する
- ノード増減時の既存データに対する再マッピングを自動化するか考慮する必要がある
利用しているサービス
Consistent Hashingを利用しているサービスとしては
といったNoSQLのデータパーティショニングや、
のようにサービスのスケーラビリティのために利用されています。