概要
ConsulではSWIMやRaftといった技術を使っています。
今回はそれらを説明します。
環境
- Consul 1.1.0
SWIM
Gossip Protocol
SWIMはGossip Protocolの一種で、主に
- クラスタのメンバ管理機能
- メンバの障害検出機能
- イベント伝播
で使われています。
こういった機能を実装しようとすると、大抵が中央集権的に情報を管理したり、各ノードがネットワーク上の全てのノードにメッセージを送信したりと言ったシステムになりますが、
Gossip Protocolは個々のノードが隣接ノードからランダムにいくつかのノードを選択し情報を伝えます。
図で表すと以下のように比較できます。
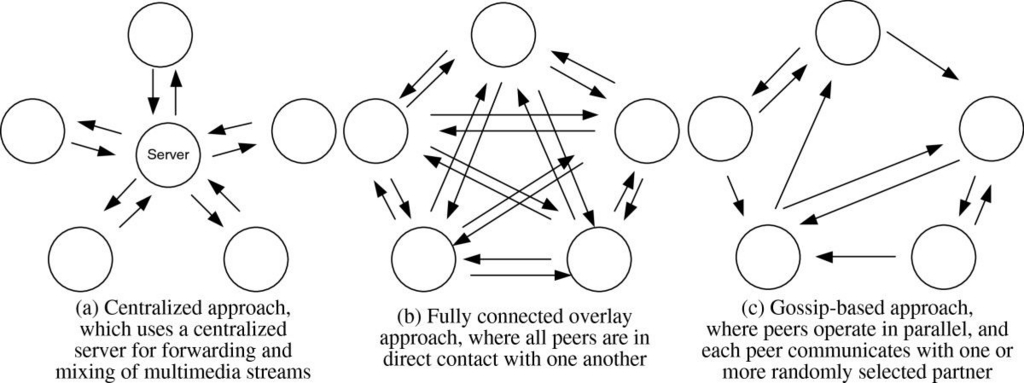
この動作を繰り返して各ノードにメッセージを共有させることで、信頼性のない通信路上で多数のノードが耐障害性の高い情報共有を行うことができるのが特徴です。
障害検知フロー
例えばメンバの障害検知のフローを説明します。
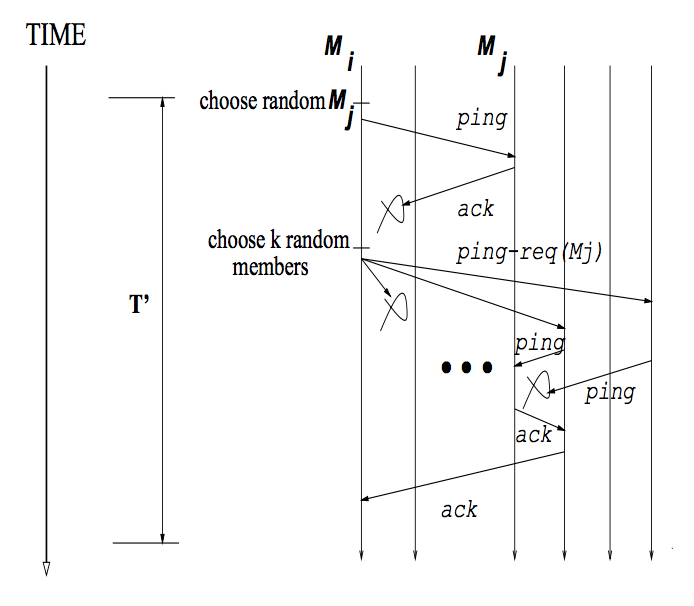
ref: Anton Kharenko: SWIM Distributed Group Membership Protocol
前提として以下があります。
- 各ノード
はクラスタメンバのリストを保持している
- 決められた時間
毎にメンバ内の他のランダムなノードの死活監視を行う
正常系と異常系のフローを説明します。
正常系
がランダムに選択した
にpingを送る
異常系
上記がうまくいかない場合、以下のような動作になります。
もし個すべてからackが返ってこなければ故障している、と判定できます。
加えてConsulではpingやackにメンバシップの情報を一緒に載せることで情報を伝搬させています。
Raft
Raftは分散合意アルゴリズムで、これによって分散しているノードであってもConsulは一貫性を持ったKVSを提供できるようになっています。
Raftのポイントとしては
- リーダー選出
- ログレプリケーション
- 安全性
の3つで、特に最初の2つを理解していれば概要が分かります。
理解するための動的スライド
こちらのページが非常にわかりやすく、理解しやすいです。まずはこちらに目を通すことをオススメします。
http://thesecretlivesofdata.com/raft/
リーダー選出
ステートの種類
各ノードは次の3つのステートになります。
- leader
- follower
- candidate
ステートの遷移
各ステートは次のように変わっていきます。
- サーバの起動直後は皆
follower followerはランダムなTimeout(150ms~300ms)を持ち、過ぎるとcandidateに変わるcandidateになると自分のtermをインクリメントする- 次に
candidateは各ノード(follower)に投票リクエストRequestVoteRPCをブロードキャストする- 各ノード(
follower)はRequestVoteRPCを受け取ったら自分のTimeoutをリセットして投票レスポンスをする
- 各ノード(
- 過半数以上(自分含む)の得票(レスポンス)を受け取った時点で
candidate->leaderになる leaderは定期的にハートビートAppendEntriesRPCを各ノード(follower)にブロードキャストするfollowerはハートビートを受け取ると自分のTimeoutをリセットする
このように遷移して、リーダーを選出します。
Raft Consensus Algorithmでは以下のように分かりやすいアニメーションが提供されてます。
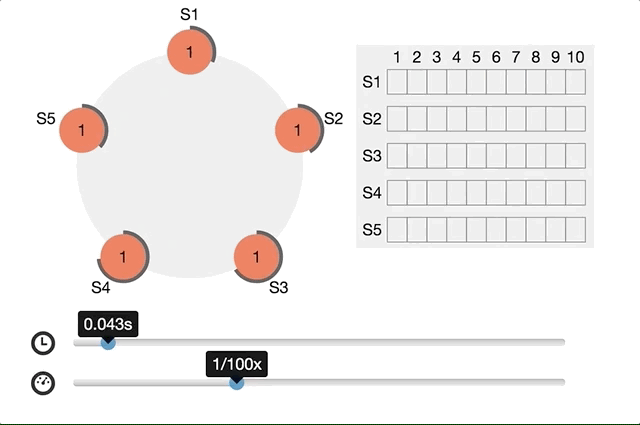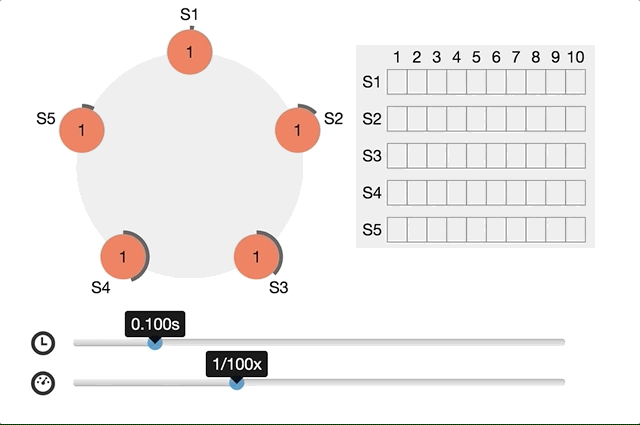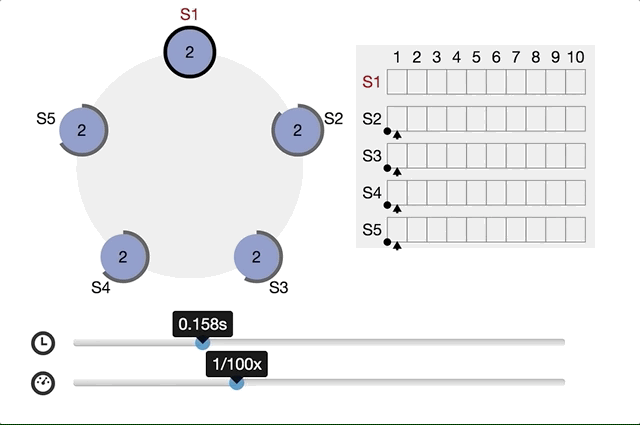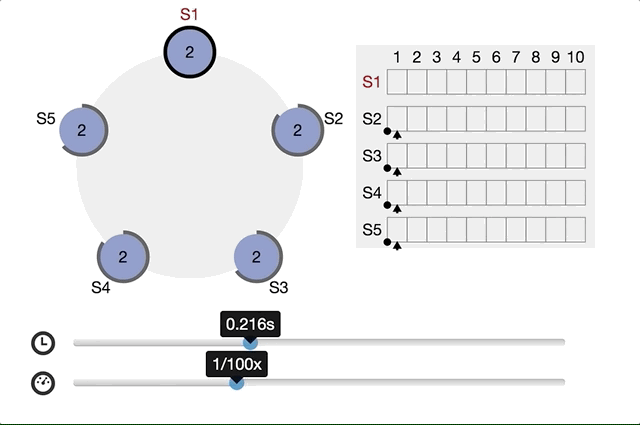
同時に複数のcandidateが生まれたらどうするか
まず前提として、
- 得票数が過半数になればリーダーになる
followerは1つのTermで最初にRequestVoteRPCを投げたcandidateに投票するので、複数のcandidateに投票されることはない
これらにより同じTermで同時に2つのリーダーが選出されることはありません。
リーダーがネットワーク的に分断されてリーダー以外が過半数以上ある場合、次Termで新しいリーダーが選出されます。この場合Termは異なるが2つのリーダーは存在します
得票数が集まらなければTimeoutし、ウェイト時間(乱数)をいれてリトライするので次のTermや次の次のTermで選出されるようになります。
ログレプリケーション
複数のノードでデータを同期する場合、データの更新による各ノードのズレが問題になってきます。
Raftではそれを次のようにしています。
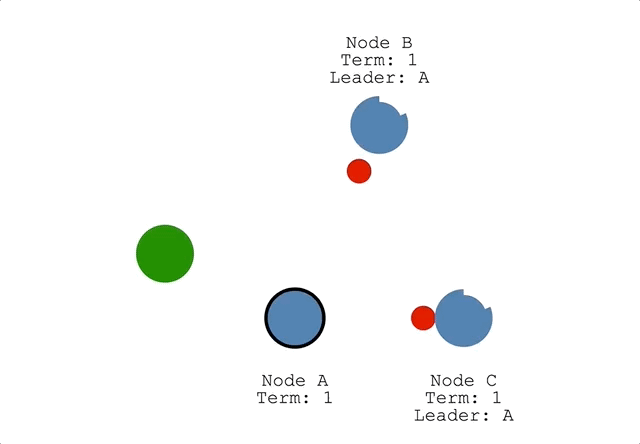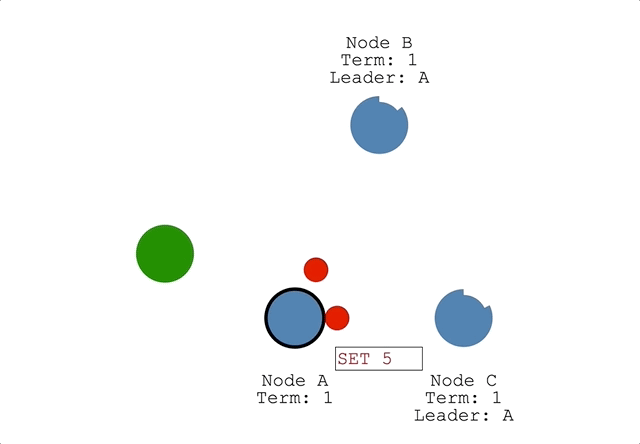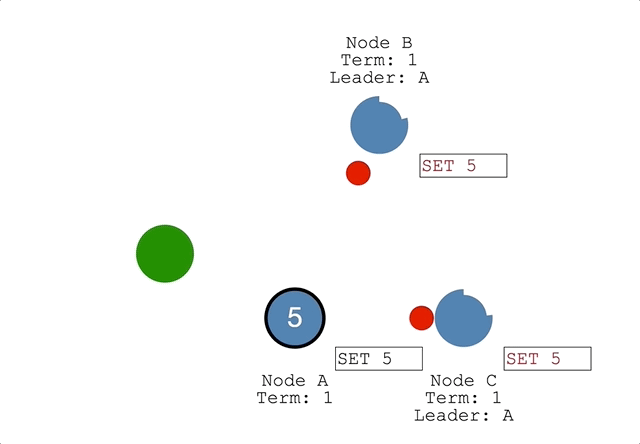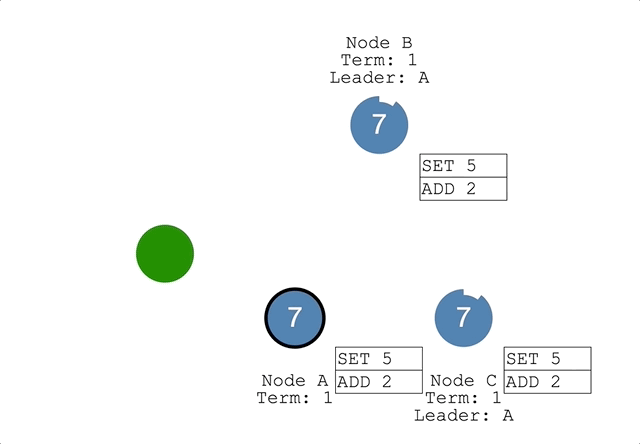
leaderがクライアントから更新処理を受け付けるleaderはそれをログとして一時的に保持するleaderは各followerにハートビートAppendEntriesRPCとともに通知する- 各
followerもログに保持する - 過半数の
followerからレスポンスが返ったらleaderは更新をコミットしてデータを更新する leaderはクライアントに成功したステータスを返すleaderは次のハートビートでコミットしたことを通知し、followerもデータを更新する
ネットワークが途切れてクラスタが分散された場合どうなる?
ネットワークが分断された場合、以下のように複数のリーダーが存在するケースがあります。
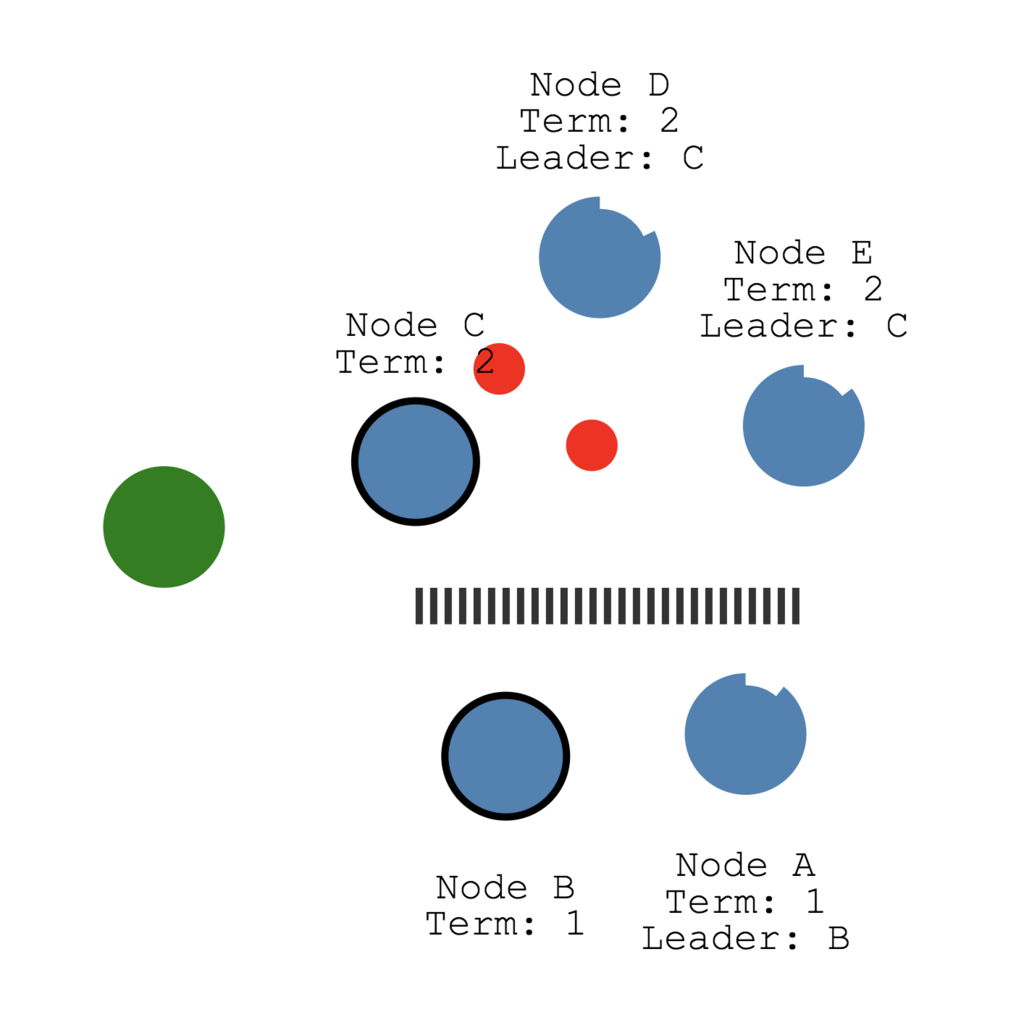
しかし下のNode B、Node Aではクライアントから更新リクエストが来ても過半数のfollowerからレスポンスを受け取ることができないので、コミットやクライアントへのレスポンスができません。
なので以下の図のように過半数ある上3つの方でデータが更新されていきます。
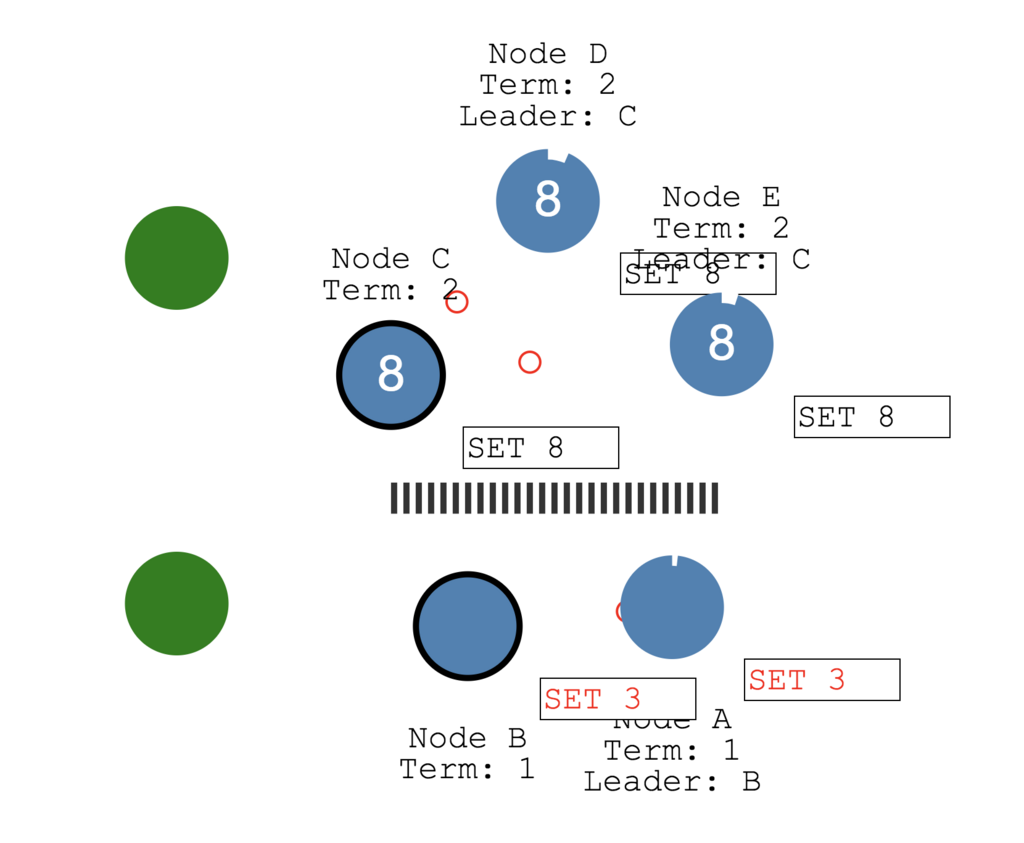
そして分断が無くなると、新しいleaderによってTermが大きい方のデータが同期されるので全体として同じステートが伝搬されることになります。
※Node A、Node Bでログにあったデータ(未コミット)はロールバックされます。
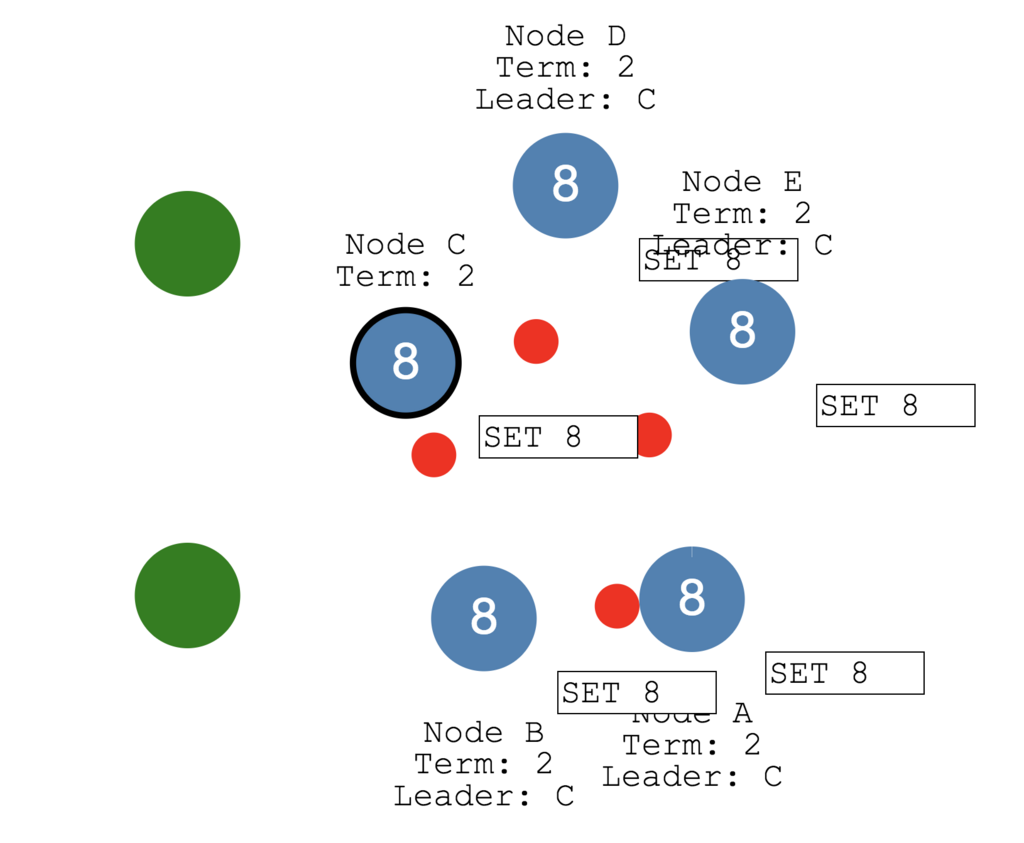
この仕組みによってRaftはデータの一貫性を担保しています。
まとめ
Service Discoveryとして採用したConsulでしたが、その中ではいろんな技術が使われていたことを学びました。