概要
分散システムにおいて同じリソースにアクセスする際にロック(排他制御)する仕組みを分散ロックといいます。
ロックを用いる背景としては主に2つあり、
| 目的 | 説明 | 具体例 |
|---|---|---|
| 効率 | 同じ作業を不必要に複数回行わないため | キャッシュのOriginへのリクエストを抑制したい(Cache stampede対策) |
| 正確性 | データの不整合が起きないようにするため | トランザクション |
Redisを分散ロックに使う場合は主に前者のケースにおいて推奨されます。
環境
- Redis 6.2.0
Redisでの分散ロック
Redisで分散ロックを実現する方法は主に2種類あります。
- SETNXを用いる
- Redlockアルゴリズムを用いる
それぞれのケースを説明します。
SETNXを用いた分散ロック
シングルインスタンスの場合SETNXを用います。
func (c *Client) updateCache(ctx context.Context, contentID string) error { // Lock nx, err := c.cli.SetNX(ctx, "lock:"+contentID, true, lockTTL).Result() if err != nil { return err } if !nx { return errors.New("failed to lock") } // Unlock defer func() { c.cli.Del(ctx, "lock:"+contentID) }() // Download heavy content // ... // Save content as cache _, err = c.cli.Set(ctx, contentID, content, cacheTTL).Result() if err != nil { return err } return nil }
この時必ずEXPIREを付けましょう。ロックを取得したクライアントが死んでしまった場合、いつまでもロックが残り続けてしまうためです。
課題
このシステムはシングルインスタンスであるため可用性が低いと言えます。
ではレプリケーションによるフェイルオーバーの機構を取り入れれば良いかというと、

このようにデータの同期が行われていればいいですが、

このように同期が遅れてClient Bでもロックが取れてしまうことが起きます。
したがって正確性を求める分散ロックとしては不十分であり、効率の最適化のために必要なロックであって時には落ちても良いケースにおいてこのSETNXを用いた分散ロックは許容されます。
Redlockアルゴリズムを用いた分散ロック
SETNXの課題であるフォールトトレラントな分散ロックを実現するためにRedlockアルゴリズムが生まれました。
詳細なロジックはRedis による分散ロック — Redis Documentation (Japanese Translation)で確認できますが、ざっくりいうとN個のマスターがあるときにクライアントは全インスタンスに対してロック取得しにいき、過半数のロックが取れたらそのクライアントはロックが取得できたと見なす、といった感じです。
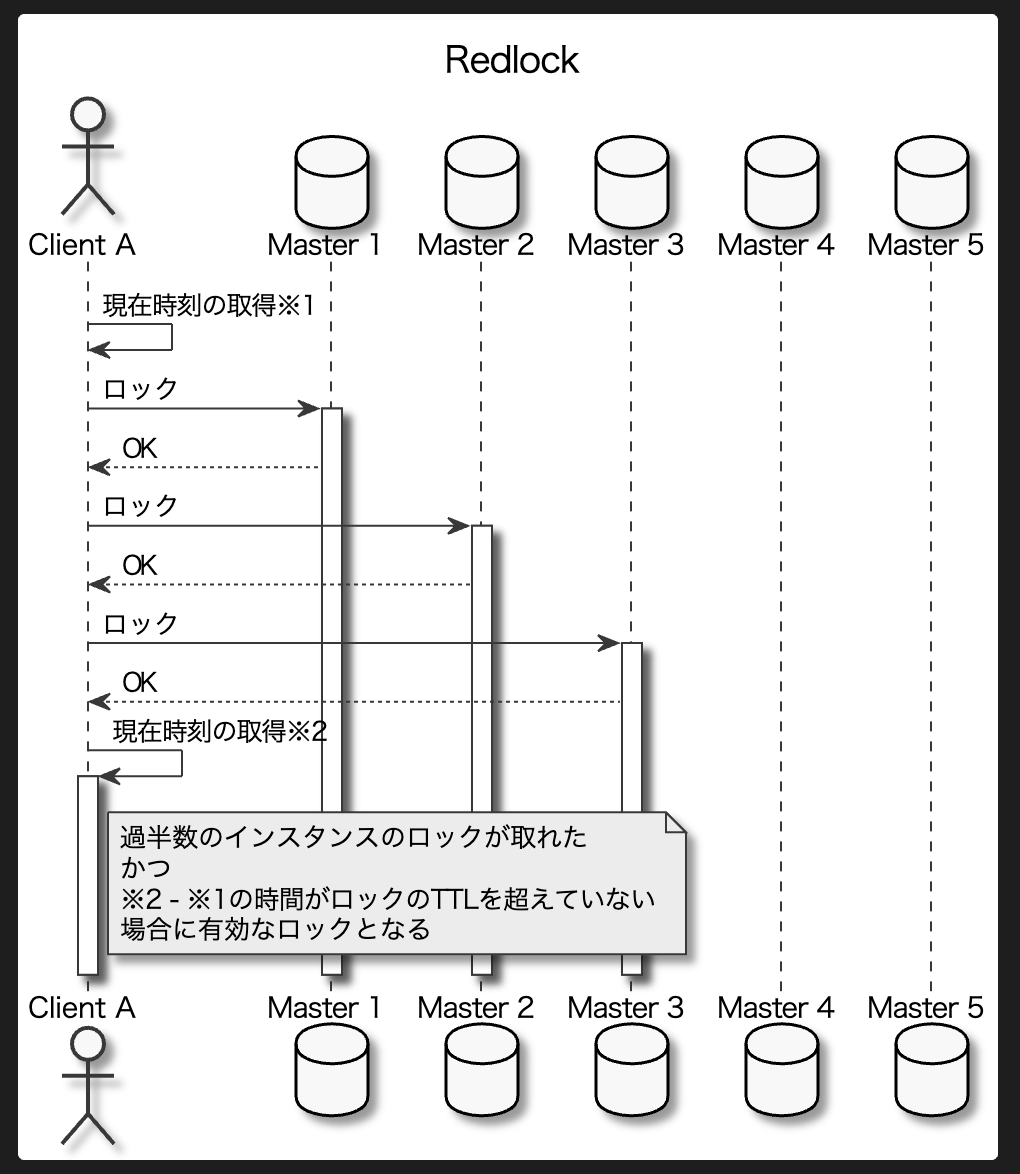
ロックの取得失敗ケース
ロックが取れないケースは主に2つあります。
過半数取れない
過半数取れなかった場合は即座に取得済みのロックをアンロックします。

有効時間が切れてしまった
またRedlockはロック取得開始時とロックが取れたタイミングで時刻を取得しますが、経過時間がロックの有効時間を過ぎてしまった場合もロックの取得に失敗したとみなして全てアンロックします。

具体的な実装
自前でRedlockのロジックを実装するのは大変なので、基本的にはライブラリを利用します。
https://redis.io/docs/manual/patterns/distributed-locks/
goの場合はgo-redsync/redsyncというものがあります。
func NewUniversal() *UClient { cli := redis.NewUniversalClient(&redis.UniversalOptions{ Addrs: []string{"localhost:6379"}, }) return &UClient{ cli: cli, } } func (c *UClient) updateCache(ctx context.Context, contentID string) error { pool := goredis.NewPool(c.cli) rs := redsync.New(pool) mu := rs.NewMutex("lock:"+contentID, redsync.WithExpiry(lockTTL), redsync.WithTries(1)) err := mu.Lock() if err != nil { return err } defer mu.Unlock() // Download heavy content // ... // Save content as cache _, err = c.cli.Set(ctx, contentID, content, cacheTTL).Result() if err != nil { return err } return nil }
課題
Redlockは可用性の高いRedis Clusterで実現されるためSETNXよりも正確性の高いロックと言えるものの、正確性を完全に保証できるかと言うと以下のケースで問題があります。

ref: How to do distributed locking — Martin Kleppmann’s blog
このようにClient 1がGCなどによって長時間ポーズする間にロックがリース(解放)されてしまうケースです。これはRedisのRedlockに限らずロックを自動リースするシステム全般で言えます。
対策として単調増加するfencing token(フェンシングトークン)を用いて、ストレージへの書き込み時に順序通りに書き込まれたかチェックする(楽観ロック)方法があります。
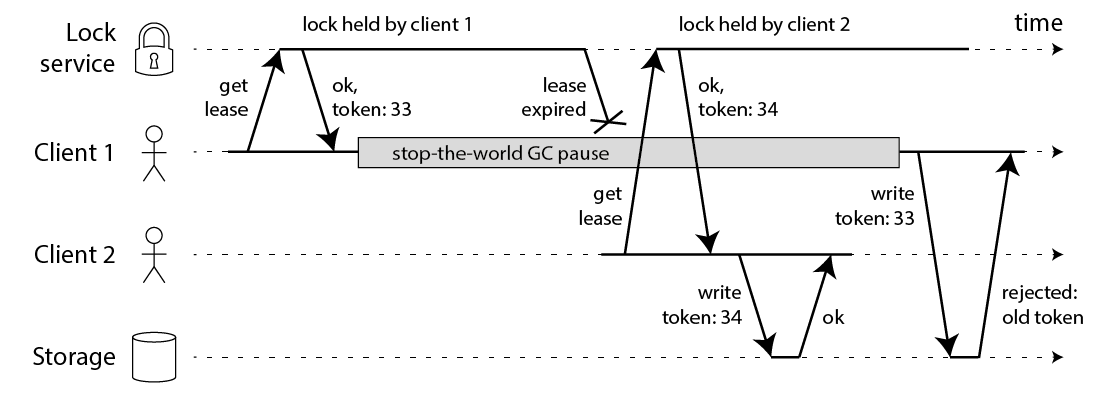
しかしRedisにはフェンシングトークンを生成する仕組みがなく、自前で用意するとなると今度はフェンシングトークンを生成するためだけにコンセンサスアルゴリズムが必要になります(スプリットブレインを起こさないため)。
なので正確性を求める場合はZookeeperのように適切なリーダー選出のアルゴリズム(Paxos)を持ったサービスを用いるのが良いです。ZookeeperのトランザクションIDであるzxidは単調増加であるのでフェンシングトークンとして利用できます。
etcdならrevision、ConsulならLockIndexがあるのでそれらを使えば同様なことが実現できると思います。
もしくはGoのようにcontextを伝播する機構があれば、リース期限に基づく(もしくはそれより短い)deadlineを設定することでcontext timeoutを起こしClient Aの処理を中断させることが可能です。
ただしこれはクライアント側の内部時計に依存するので、内部時計のズレが大きいと防げません
まとめ
Redisを用いた2種類の分散ロックの方法を紹介しました。
効率のための分散ロックをであればRedisは良い選択肢であり、一方で正確性を求める場合は
Zookeeper, etcd, Consul > Redlock > SETNX
のような選択になります。