概要
BigQueryはIAMロールを設定する際にハマる事が多いので、アーキテクチャを理解しておくときちんと権限付与することができます。
BigQueryのアーキテクチャ
BigQueryのアーキテクチャは以下のように
- ストレージ
- コンピュート
の大きく2つに分かれています。

ref: An overview of BigQuery's architecture and how to quickly get started | Google Cloud Blog
そのため権限もこの2つを意識して設定する必要があります。
またストレージに関しては↓で説明したようなリソース階層(レベル)も意識する必要があります。
具体的には
- プロジェクト(組織、フォルダ)
- データセット
- テーブル
と対象が細かく分かれています。
権限設定
BigQueryの事前定義ロールは以下にまとまっています。
https://cloud.google.com/iam/docs/understanding-roles?hl=ja#bigquery-roles
その中でよく使うのは以下でしょう。
| ロール | 何ができる | 対象リソース |
|---|---|---|
| BigQuery ジョブユーザー (roles/bigquery.jobUser) |
クエリなどジョブを実行する権限 | コンピュート |
| BigQuery データ閲覧者 (roles/bigquery.dataViewer) |
データセットに対する読み取り権限 | ストレージ |
| BigQuery データ編集者 (roles/bigquery.dataEditor) |
データセットに対する書き込み権限 | ストレージ |
通常の使い方
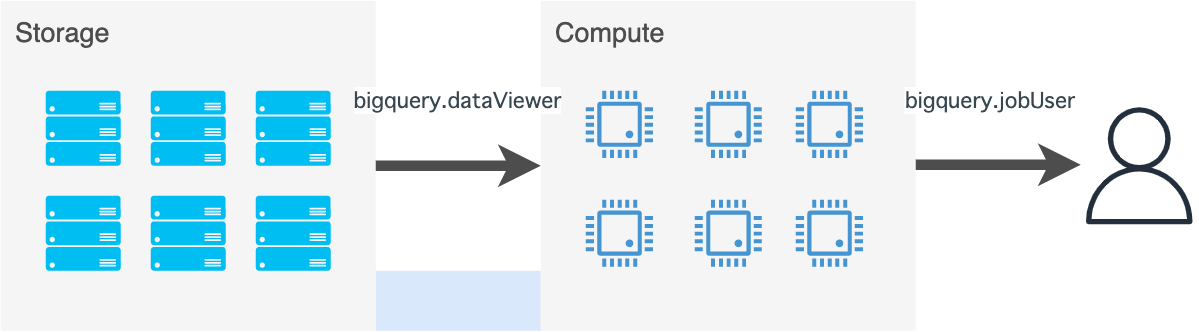
BigQueryに溜めたデータをクエリで分析したい用途の場合です。
- ストレージからデータセットを読み込んで
- コンピュートで分析したい
ので、roles/bigquery.dataViewer、roles/bigquery.jobUserそれぞれの権限が必要です。
よくある間違い
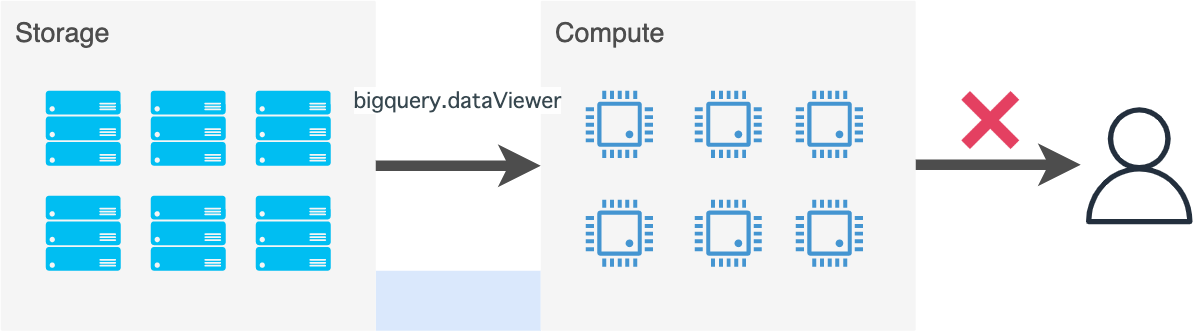
よくある間違いとしては片方のみ権限を付与する場合です。
roles/bigquery.dataViewerだけだと分析(コンピュート)できないですし、
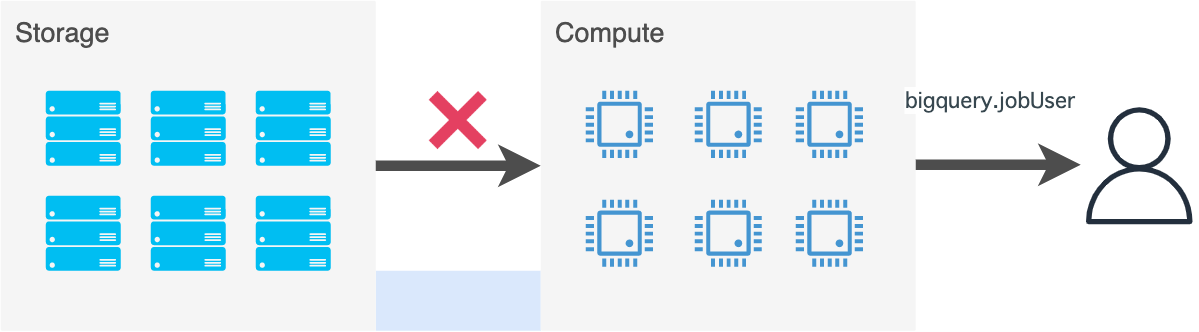
roles/bigquery.jobUserだけではそもそもデータにアクセスできません。
BigQueryにデータを保存したい場合
例えばCloud LoggingのデータをBigQueryに保存したいようなケースでは、単にストレージへの書き込み権限があればいいのでroles/bigquery.dataEditorだけで済みます。

アーキテクチャを理解していないとついついroles/bigquery.jobUserもつけちゃいがちですが、本来は不要です。
※ただしbq loadコマンドやSDKでは内部でジョブを作成するためbigquery.jobs.create権限が必要になります
他プロジェクト連携する場合
次は他社・他プロジェクトと連携する場合です。
BigQueryのようにビッグデータを扱うサービスはデータを外部から受け取って分析したり、逆に自分たちのデータを専門の分析チームに分析してもらうケースがあります。
自社がデータを持ち、他社で処理する場合
自社のデータを他社に連携する場合は、自社(Project A)のデータセットに対するroles/bigquery.dataViewerを他社に付与します。
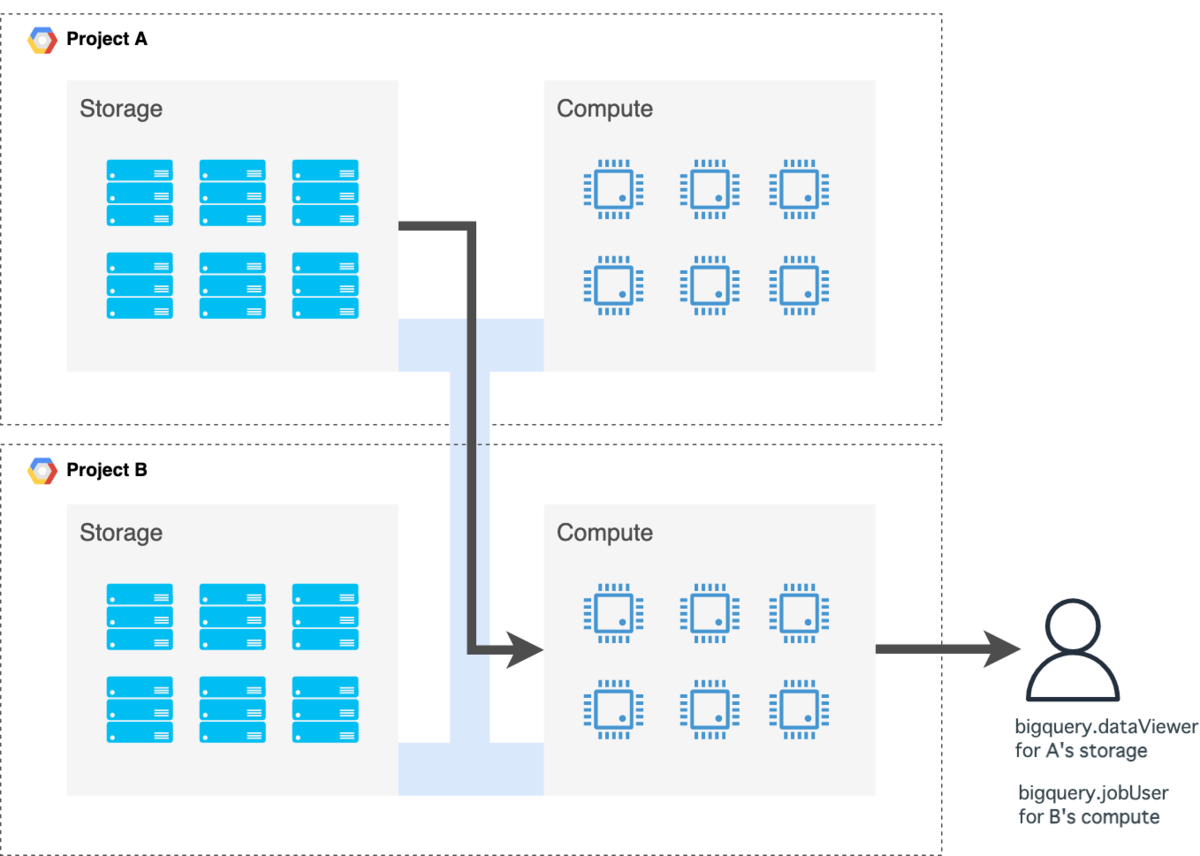
ポイントはあくまでコンピュート権限は他社(Project B)自身のものを使ってもらう点です。
よくある間違い
よくある間違いとしては、ストレージのアクセス権限だけでなくコンピュート権限roles/bigquery.jobUserも付与してしまうことです。
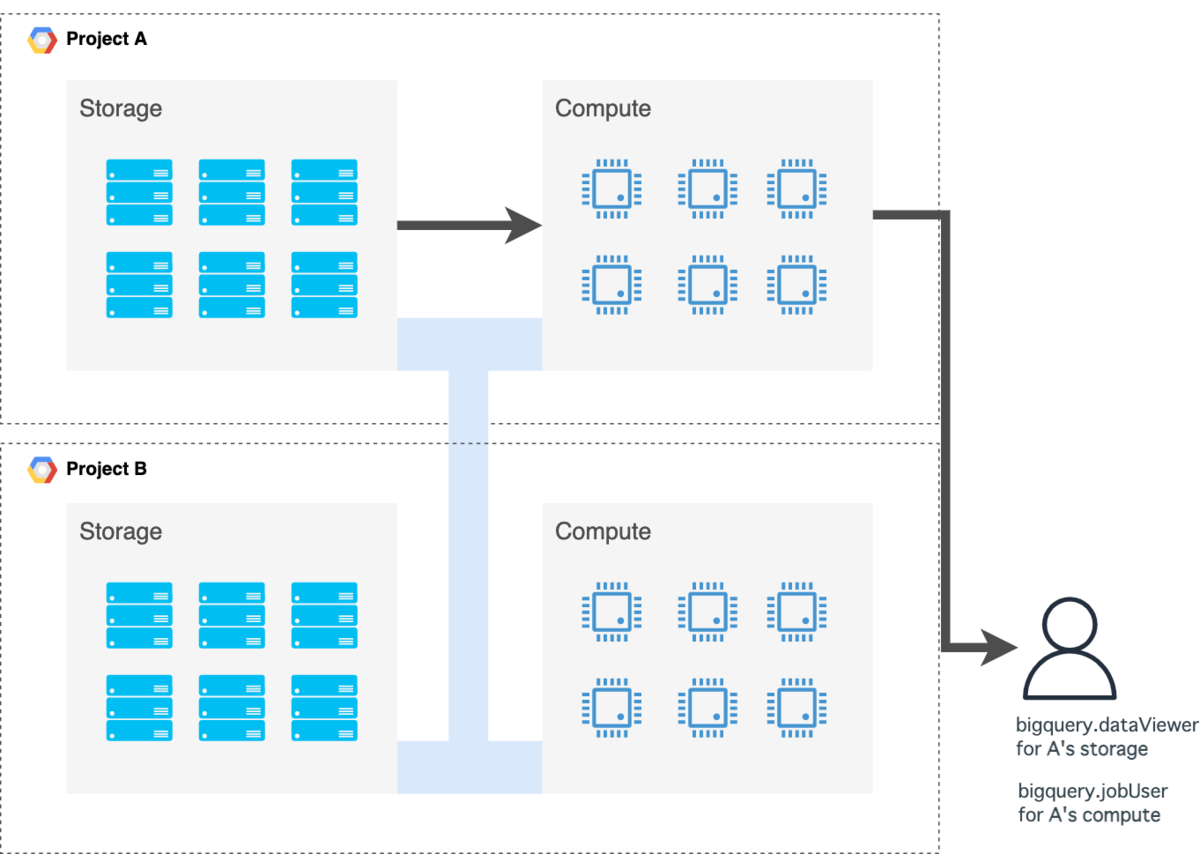
こうすると他社(ProjectB)のデータも自社(ProjectA)のBigQueryで分析できてしまうので、分析にかかるお金もProjectA側になってしまいます。

ProjectB側に悪意がなくとも、オペミスなどでProjectA側のコンピュートを利用してしまう可能性はあるので付与しないよう気をつけましょう。
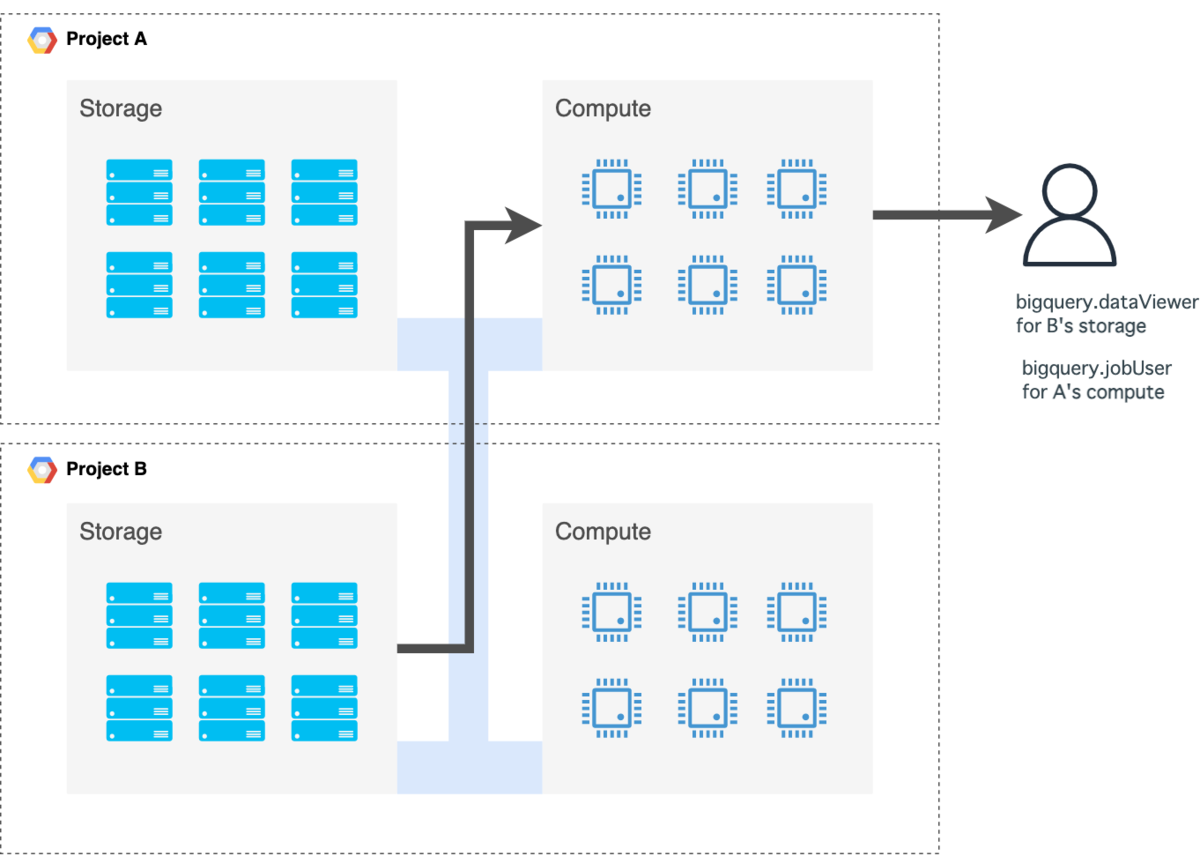
他社がデータを持ち、自社で処理する場合
他社(ProjectB)のデータセットに対するアクセス権限を付与してもらい、コンピュート権限は自社(ProjectA)のものを付与しましょう。
その他
Terraformでの設定
terraformではそれぞれ権限を設定するリソースが分かれているので必要に応じて記述します。
ストレージに対する権限
最初に述べたように対象リソースが細かいので、それぞれのやり方を紹介します。
プロジェクトレベル
プロジェクト全てのデータセットを見れるため権限が強すぎて推奨されません。
resource "google_project_iam_member" "editor" { project = "my-project" role = "roles/bigquery.dataEditor" member = "user:jun06t@example.com" }
データセットレベル
通常は権限の大きさと柔軟性のバランスが良いこの書き方を選択することが多いと思います。
resource "google_bigquery_dataset_iam_member" "editor" { dataset_id = google_bigquery_dataset.dataset.dataset_id role = "roles/bigquery.dataEditor" member = "user:jun06t@example.com" } resource "google_bigquery_dataset" "dataset" { dataset_id = "example_dataset" }
テーブルレベル
テーブルが固定化されていて最小権限の原則に則るならこの書き方になるでしょう。
resource "google_bigquery_table_iam_member" "editor" { dataset_id = google_bigquery_dataset.dataset.dataset_id table_id = google_bigquery_table.table.table_id role = "roles/bigquery.dataEditor" member = "user:jun06t@example.com" } resource "google_bigquery_dataset" "dataset" { dataset_id = "example_dataset" } resource "google_bigquery_table" "table" { dataset_id = google_bigquery_dataset.dataset.dataset_id table_id = "example_table" }
コンピュートに対する権限
こちらはプロジェクト以上のリソースです。
resource "google_project_iam_member" "job_user" { project = "my-project" role = "roles/bigquery.jobUser" member = "user:jun06t@example.com" }
AuthoritativeかNon-authoritativeか
terraformでは権限に関して
| 種別 | 説明 |
|---|---|
| Authoritative | それが唯一の権限設定になり、既存の権限設定(memberなど)があれば上書きしてしまう |
| Non-authoritative | 既存の権限に影響を与えない |
がありますが、Non-authoritativeなxxx_iam_memberが推奨されます。
ref: Terraform を使用するためのベスト プラクティス | Google Cloud
まとめ
BigQueryのアーキテクチャを理解することで、困りがちな権限設定もすんなり理解することができました。