概要
データベースを扱うと、パフォーマンス向上を考えた際に必ず出てくるコネクションプーリングについてです。
今回はコネクションプーリングの種類とその特徴についてと、各データベースの特性に合わせてどんな選択を取るのが良いかを説明します。
コネクションプーリング
コネクションプーリングのメリットは
- コネクション作成時のオーバヘッドの削減
- リソースの再利用による効率化
です。後述しますが、例えばPostgreSQLは1コネクション=1プロセスモデルであるため、
- 3つのWebサーバ
- 各インスタンスは1秒あたり100件のリクエスト
- 各リクエストで3つのクエリを実行
であった場合、接続プールがなかったとすると 1秒あたり900件のデータベース接続が開閉=毎秒900のプロセスが作成・破棄されるという無駄な処理が発生します。
そこで接続をプール(保持)し、再利用することで無駄を省くのがコネクションプーリングです。
クライアントサイドコネクションプーリング
コネクションプーリングはアプリケーション(クライアントサイド)で実現する方法と、ミドルウェアレイヤのProxyで実現する方法が主にあります。
クライアントサイドではSDKが内部でコネクションを保持してくれます。

メリット
- アプリケーション直結なので導入が容易
- ライブラリ追加で始められる。
- 接続確立のオーバーヘッドを減らし、レスポンス高速化に直結
- アプリケーション側で細かくポリシー制御が可能(接続数、タイムアウト)
デメリット
- アプリサーバの数 × プールサイズで接続が増えるため、DB 側のコネクションが爆発しやすい。
- それぞれのプールで設定がバラつくと、接続管理の統一が難しくなる。
- プールの設定不備(最小・最大数の不整合)で 一斉再接続や接続枯渇のリスクも
Proxy型コネクションプーリング
一方Proxy型では、アプリケーションサーバとデータベースサーバの間にPgpool-IIやPgBouncerなどの接続管理のためのミドルウェアを挟んでプーリングさせます。
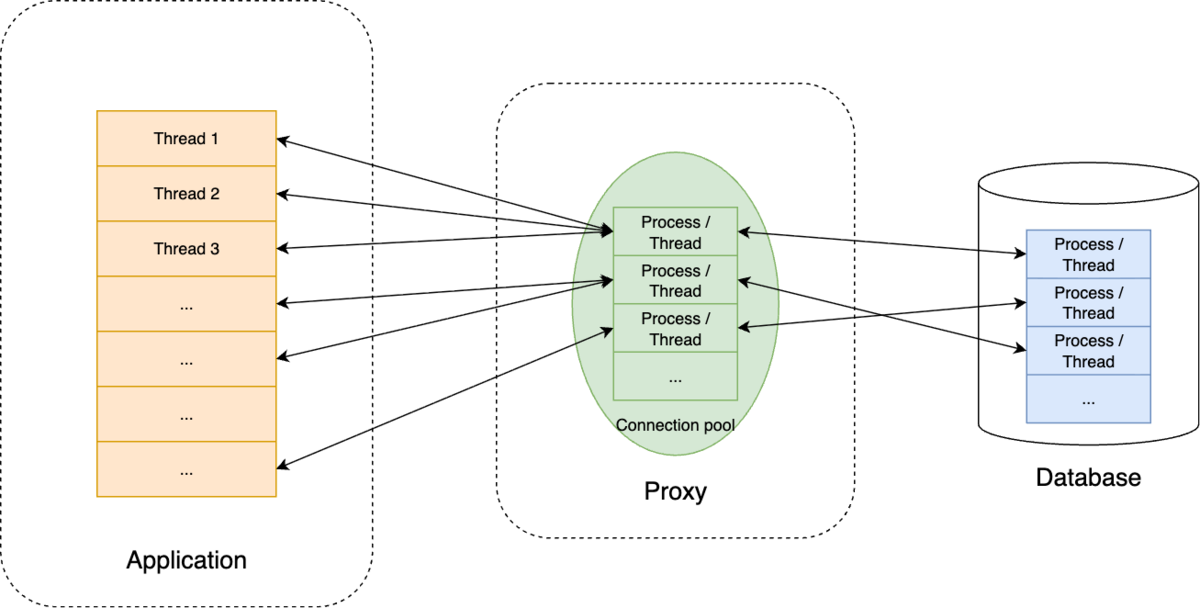
メリット
- データベースへの接続負荷を大幅に削減可能
- クライアント数に関係なく一定数で管理できる
- アプリケーションにプール管理のコードを持たせずに済む(集約・一元管理)。運用が楽。
- 接続数を DB 側で集中管理できるため、負荷予測と制御がしやすい。
デメリット
- プロキシの運用負荷(監視・スケーリング・冗長構成)が必要。
- プロキシを経由するので、レイテンシが増す可能性がある。
データベース毎のコネクションの作り方
次にデータベース毎のコネクションの作り方を説明します。
PostgreSQL
PostgreSQLは1コネクション = 1プロセスモデルです。
メリット
- OSプロセスに隔離されるため、安定性・安全性が高い
- ある接続がクラッシュしても他に影響しにくい
- 実装がシンプルでデバッグ・運用がしやすい。
- CPU資源をプロセス単位で扱えるため、マルチコアで安定して動作。
- OSプロセスに隔離されるため、安定性・安全性が高い
デメリット
- プロセス生成・コンテキストスイッチのオーバーヘッドが大きい。
- 大量接続に弱い(数千〜数万接続はプロセス数的に厳しい)。
- 接続管理を外部(PgBouncer等)に委ねるケースが多い。
なのでPostgreSQLは基本的に最大接続数の上限値が低く設定(デフォルト100)されています。
MySQL
MySQLは1コネクション = 1スレッドモデルです。
- メリット
- プロセスより軽量なので、Postgresより高い接続数に耐えやすい。
- 実装も比較的シンプル。運用実績も豊富。
- スレッドプールを導入すれば、さらに効率的に接続を処理できる。
- デメリット
- 1接続1スレッドなので、数万接続レベルではスレッド数がボトルネックになりやすい。
- スレッドスタックのメモリ消費が積み上がる。
- スレッド切り替えのオーバーヘッドがある。
なのでPostgreSQLほどコネクション数が問題になることは少ないです。
MongoDB
MongoDBはイベントループ + スレッドプールモデルです。
PostgreSQLが1996年、MySQLが1995年に生まれた一方で、MongoDBは2009年と比較的最近です。
でまとめたように、当時のC10K問題のような大量接続に対応してこのモデルになったと思われます。
NoSQL自体がデータ整合性よりもスケーラビリティを重視したソリューションですしね。
- メリット
- 接続が非常に軽量
- ノンブロッキングI/Oで管理するため、数万〜数十万接続にも耐えやすい)
- CPUバウンド処理はスレッドプールに渡すので効率が良い。
- 大規模スケールやクラウド環境に向いている設計。
- 接続が非常に軽量
- デメリット
- 実装が複雑で、デバッグやチューニングの難易度が高い。
- イベント駆動特有の「1つの処理が長引くと全体に影響」というリスク
- 多数の接続を捌けるが、重いクエリが多いと結局スレッドプールが詰まる。
まとめると以下になります。
- PostgreSQL = 安定・安全(プロセス分離)
- MySQL = バランス型(スレッドで軽量化)
- MongoDB = スケーラビリティ優先(イベントループ)
とは言えPostgreSQLが大規模トラフィックに向いていないのか?と言われればPgBouncerなどのコネクションプーリングなどを挟めば対応できるので、互換性やプロダクトの思想を変えてまでスレッドモデルなどに移管することはないと推測しています。
データベースとコネクションプーリング
各データベース毎のコネクションモデルと、コネクションプーリングの影響度を考えると以下の様になります。
| データベース | クライアントサイドプール | Proxy型プール | 備考 |
|---|---|---|---|
| PostgreSQL | 必須 | 強く推奨(PgBouncer/Odyssey) | プロセスモデルで重いので両方併用が定石。 |
| MySQL | 推奨 | 中規模以上は有効(ProxySQL) | スレッドモデルで比較的軽いが、大規模接続はProxyで制御すると安定。 |
| MongoDB | ドライバが標準でプール持ち(十分) | 通常不要 | 接続軽量。Proxyを置くのはシャーディングや多リージョンの特殊用途のみ。 |
まとめ
コネクションプーリングの種別と、各データベースのコネクションモデルについて紹介しました。
データベース毎の特性を理解した上で、どういったコネクションプーリングを採用するか選定するのが良いでしょう。