概要
gRPCでのバランシングをClient-Sideで直接実装する方法の紹介です。
gRPCはPolyglot(様々な言語で扱う)を意識しているので、gRPC自体の仕様が策定→各言語がそれに則って実装となります。
なので「元々はこういう実装だったけど、他の言語と統一してこう変更したよ」みたいなissueをちょこちょこ見ます。
結果これまでの書き方がいつのまにかdeprecatedになってたりするので、以前の書き方から遡って調べてみました。
環境
- go v1.13.6
- grpc-go v1.26.0
- kubernetes v1.14.8
Client-Side LBの書き方
2世代前
こちらの書き方です。日本語記事はこの書き方が多め。
r, _ := naming.NewDNSResolverWithFreq(5 * time.Second)
balancer := grpc.RoundRobin(r)
conn, err := grpc.Dial(endpoint,
grpc.WithInsecure(),
grpc.WithBalancer(balancer),
)
が、naming packageもgrpc.RoundRobin()もgrpc.WithBalancer()も全てdeprecatedです。
追記:v1.30.0から消えてました。
検証環境で実行したところ、deprecatedなせいなのか環境とマッチしなかったのかうまく動きませんでした。
Endpoint: headless-svc:8080 2020/01/16 21:07:36 rpc error: code = Unavailable desc = there is no address available
1世代前
こちらの書き方です。英語記事でいくつか。
resolver.SetDefaultScheme("dns")
conn, err := grpc.Dial(endpoint,
grpc.WithInsecure(),
grpc.WithBalancerName(roundrobin.Name),
)
ポイントは
resolver.SetDefaultScheme("dns")
とするところで、デフォルトだとpassthroughなためround robinしてくれないようです。
が、こちらgrpc.WithBalancerName()が既にdeprecated。
さっきのgrpc.WithBalancer()のドキュメントにgrpc.WithBalancerName()を使ってとあったのに。。
現在
grpc.WithBalancerName()には
Deprecated: use WithDefaultServiceConfig and WithDisableServiceConfig instead. Will be removed in a future 1.x release.
とあるのでgrpc.WithDefaultServiceConfig()を使った書き方です。
これは以下で定義されているservice configというを使うのですが、
grpc/doc/service_config.md at master · grpc/grpc · GitHub
goDocで関数の引数を見て分かるように、JSON文字列を直接書かなくてはいけない辛い仕様の模様。
一応structはあるがdeprecatedで使うべきではないとのこと。
resolver.SetDefaultScheme("dns") conn, err := grpc.Dial(endpoint, grpc.WithInsecure(), grpc.WithDefaultServiceConfig(fmt.Sprintf(`{"LoadBalancingPolicy": "%s"}`, roundrobin.Name)), )
ref: golang grpc 客户端负载均衡、重试、健康检查
しかもservice configのloadBalancingPolicyフィールドは既にdeprecatedとあり、ここから先はまだ不明確でした。
追記
loadBalancingPolicyフィールドは既にdeprecated
こちらのコミットでloadBalancingConfigというフィールドに変わっていました。また中も配列になりました。
-grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy":"round_robin"}`), +grpc.WithDefaultServiceConfig(`{"loadBalancingConfig": [{"round_robin":{}}]}`),
追記終わり
イメージとしてはClientがバランシングポリシーやretryロジックなどを考えず、Service側であらかじめ定義してJSONを公開→Clientはそれを使う、という流れのようです。
例えば以下のようなServiceConfig.jsonがService側から公開されます。Client側が好き勝手やるとService側のキャパシティプランニングがしにくいので、Service側でコントロールできるようにということでしょうか。
{ "loadBalancingConfig": [{"round_robin":{}}], "methodConfig": [ { "name": [ { "service": "namespace1.ServiceA" }, { "service": "namespace2.ServiceB" } ], "timeout": "1s", "retryPolicy": { "maxAttempts" : 5, "initialBackoff" : "0.1s", "maxBackoff": "30s", "backoffMultiplier": 3, "retryableStatusCodes": [ "UNAVAILABLE" ] } } ] }
サービスメッシュでcontrol-planeとdata-planeがやっているxDSの流れにも似ていますね。
その他ポイント
バックエンドのIP群をどう把握するか?
Client-Side LBの場合、バックエンドにどんなPodがあるか(Pod IP)を把握しておく必要があります。
選択肢としては以下になります。
- Headless ServiceのようなバックエンドのIPが返るServiceDiscoveryを使う
- watch APIでPodのイベントを監視する
手軽なのはKubernetesで提供されているHeadless Serviceです。
しかし一方で次に話すClient側のresolveタイミングが問題になります。
watch APIの方は一部自前で実装する必要があります。しかし大抵のライブラリはsubscribeできる形のメソッドを提供してるので、イベント発火時に即座に変更できるメリットがあります。
DNSのresolveタイミングは?
Podは頻繁に作成・削除されるので、対象IP群を常にチェックする必要があります。
単純に考えるとpollingですが、DNSに負荷をかけるpollingは良くないとされています。
DNS polling is in general a bad idea. In the presence of round-robin DNS servers it would cause actual harm. High-frequency DNS polling can cause quite a bit of load to a critical system, which is dangerous.
grpc-goでは30分毎にpollingによるresolveが行われますが、これも将来的には消したいようです。
じゃあどうするの?
grpcのコネクションはコネクションが切れた時に再resolveするという実装になっています。

なので
- スケールインした時は即resolveしてくれる
- ローリングアップデートはスケールアウト→スケールインなので↑と同じく問題ない
- スケールアウトは最大30分待つ
ということになります。
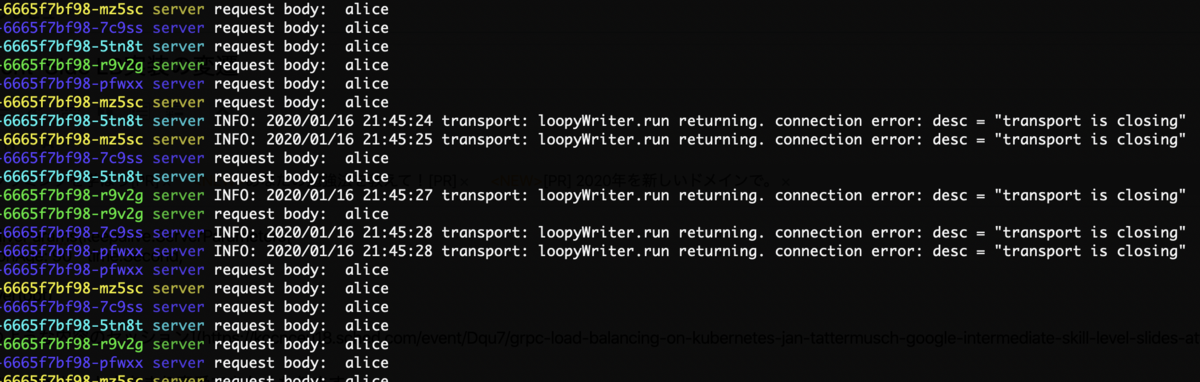
そこでサーバ側で以下のようにコネクションを定期的にリセットする実装を導入すべきと言っています。
opt := grpc.KeepaliveParams(keepalive.ServerParameters{
MaxConnectionAge: 90 * time.Second,
})
s := grpc.NewServer(opt)
kubeconでもそのような内容のセッションがありました。
ちなみにjitterが入っているので、durationが短いと最初は接続を切るタイミングが近いですが、時間が経つとどんどんズレていってくれます。

結局どう実装すればいいか
どの世代の実装を使うべきか
サービス側がクライアントにServiceConfigを提供する仕組みが整っていればgrpc.WithDefaultServiceConfig()が良いと思います。
そうでなければgrpc.WithBalancerName()がまだ使える&書きやすいのでそちらが良いと思います。
DNSのresolveタイミングは?
ケースによります。
Podはほぼ固定台数。オートスケールはしない
であればgRPCのロジックのままで大丈夫で、MaxConnectionAgeも設定しなくてOKです。
オートスケールする。再接続のオーバーヘッドは無視できる
MaxConnectionAgeを設定しましょう。
オートスケールする。再接続のオーバーヘッドも無視できない
MaxConnectionAgeを長めに設定するか、watchAPIを利用してリアルタイムでDNSのresolveを行います。
もしくはProxyモデルLBのようにEnvoyを挟んだりする形が良いと思います。
サンプルコード
Client-Side LBのgRPC側の実装のサンプルコード
kubernetesのマニフェストyamlのサンプルコード