概要
Podの冗長化をする上でマルチゾーン構成にしたい場合
Pod Topology Spread Constraints | Kubernetes
上記のPod Topology Spread Constraintsを使うと実現できます。
環境
- Kubernetes v1.24
Pod Topology Spread Constraints
Pod Topology Spread ConstraintsはPodをスケジュール(配置)する際に、zoneやhost名毎に均一に分散できるようにする制約です。
ちなみにkubernetesのスケジューラーの詳細はこちらの記事が非常に分かりやすいです。
パラメータ
主に使うパラメータは以下です。
| パラメータ | 説明 | デフォルト値 |
|---|---|---|
| topologyKey | スケジュールの制約条件に使う Node Label | - |
| maxSkew | zone間のPod数の差の上限 0より大きい数値でないといけない |
- |
| whenUnsatisfiable | DoNotSchedule: maxSkewを満たさない場合、そのトポロジーにスケジュールしない ScheduleAnyway: maxSkewを満たさない場合、skewを減らすようにスケジュールする |
DoNotSchedule |
| labelSelector | スケジュール対象の Pod Label | - |
これら以外のパラメータはドキュメントを参照して下さい。
ref: Pod Topology Spread Constraints | Kubernetes
skewとは
skew(歪度)の計算式は以下の通りです。
以下の図を元に考えると、
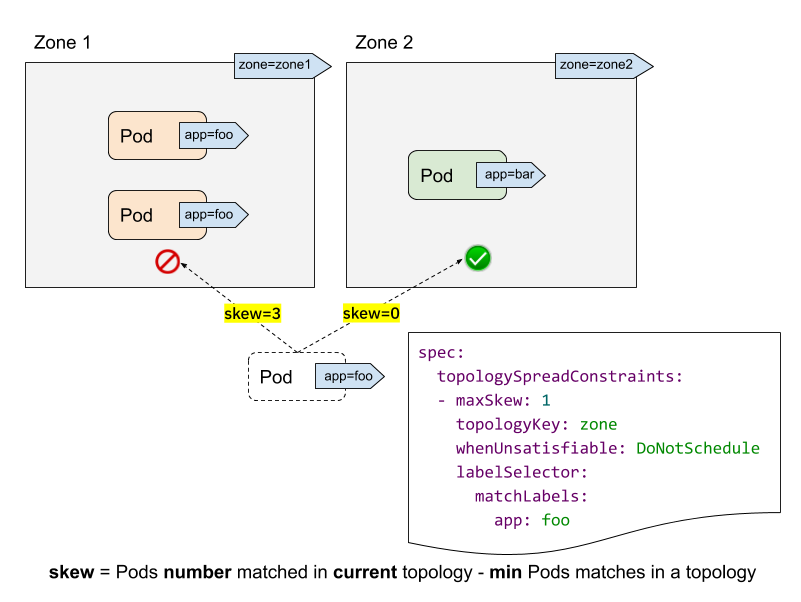
ref: https://kubernetes.io/blog/2020/05/introducing-podtopologyspread/
maxSkew=1として
zone1に配置しようとした時
- 現状zone1にPodが2つある。
- 1つスケジュールすると3つになる。
- 各zoneで最小のPodはzone2の0。
- 計算式3−0=3でmaxSkewに違反(3>1)する
zone2に配置しようとした時
- 現状zone2にPodはない
- 1つスケジュールすると1つになる。
- 各zoneで最小のPodは同じくzone2の1。
- 計算式1−1=0でmaxSkewを満たす(0≦1)
となります。
既に均一だったら?
既にzone1とzone2が均一(例えば2 Podずつ)の場合は、
- zone1にスケジュールすると3
- 各zoneで最小のPodは同じくzone2の2。
- 計算式3−2=1でmaxSkewを満たす(1≦1)
となります。
なのでmaxSkewは0より大きな数値でないといけません。
デフォルト設定
Kubernetes v1.24からはクラスタレベルで次の制約がデフォルト設定されています。
defaultConstraints: - maxSkew: 3 topologyKey: "kubernetes.io/hostname" whenUnsatisfiable: ScheduleAnyway - maxSkew: 5 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway
設定方法
具体的な設定方法です。
Deploymentに次のようにtopologySpreadConstraintsを設定します。
apiVersion: apps/v1 kind: Deployment metadata: name: my-app spec: replicas: 6 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - name: nginx image: nginx:1.25 ports: - containerPort: 80 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: my-app
またラベルが増えるのでこんがらがる人は以下の記事を参考にして下さい。
注意点
調査時や導入して気になった点を挙げます。
デプロイ時の旧Podも計算対象に入る
DeploymentのstrategyによってはAZ分散がうまく行かないパターンがあります。
例えば
- replica: 3 (zone-a: 1, zone-b: 1, zone-c: 1)
- Deploymentのstrategy.rollingUpdate.maxSurge: 50%
のような時に、
- zone-a, zone-bに1Podずつ、計2Pod追加される
- zone-a: 2, zone-b: 2, zone-c: 1
- zone-bの旧PodがTerminate
- zone-a: 2, zone-b: 1, zone-c: 1
- 新しいPodがzone-bに追加される(maxSkewを違反しないため)
- zone-a: 2, zone-b: 2, zone-c: 1
- zone-aの旧PodがTerminate
- zone-a: 1, zone-b: 2, zone-c: 1
- zone-cの旧PodがTerminate
- zone-a: 1, zone-b: 2, zone-c: 0
といったことが起きることがあります。
ゾーン障害から復旧してもリバランスはされない
Pod Topology Spread ConstraintsはあくまでPodスケジュール時の制約であるため、
- replica: 6 (zone-a: 2, zone-b: 2, zone-c: 2)
でバランス良く分散されていた状態で、zone-cにゾーン障害が発生した場合
- replica: 6 (zone-a: 3, zone-b: 3, zone-c: 0)
となります。
その後zone-cが復旧したとしても、現状のPodをEvictしてzone-cにリバランスしてはくれません。
(もちろんPodの削除やDeploymentが発生すればzone-cにスケジュールされます)
DoNotScheduleだとストックアウト時に配置できなくなる
にあるように、ストックアウトによって一部のゾーンのノードが増やせない状態に陥った場合に、maxSkew=1だとPodが配置できなくなる状況に陥ります。
- zone-cでノードのストックアウトが起きる
- zone-cのノードのリソースがなくなりPodがこれ以上置けない
- topologySpreadConstraints
- maxSkew: 1
- whenUnsatisfiable : DoNotSchedule
という状況の場合、replica: 6だとすると
- zone-aにPodをスケジュール→Running
- zone-bにPodをスケジュール→Running
- zone-cにPodをスケジュールするが配置できるノードが無い→Pending
- zone-aにPodをスケジュールしようとするがzone-cとのPod差が1ある状態で
DoNotSchedule制約がある→Pending - zone-bにPodをスケジュールしようとするがzone-cとのPod差が1ある状態で
DoNotSchedule制約がある→Pending
ということになります。
なので次に紹介するDeschedulerと、whenUnsatisfiable: ScheduleAnywayの組み合わせがベターと言えそうです。
Deschedulerとの組み合わせ
前述の
- デプロイ時に偏る可能性
- ゾーン障害復旧後の偏りが直らない
といった問題を解決する方法としてDeschedulerがあります。
これは条件に違反したPodをEvictさせる仕組みです。
こちらは先程と逆で、PodのEvictのみに責務を持っています。
- Deployment
- CronJob
- Job
の3通りの使い方があり、以下でサンプルコードが提供されています。
https://github.com/kubernetes-sigs/descheduler/tree/master/kubernetes
--policy-config-fileには次のようなポリシーを用意します。ConfigMapなどで用意するのが良いでしょう。
apiVersion: "descheduler/v1alpha2" kind: "DeschedulerPolicy" profiles: - name: ProfileName pluginConfig: - name: "RemovePodsViolatingTopologySpreadConstraint" args: constraints: - DoNotSchedule - ScheduleAnyway plugins: balance: enabled: - "RemovePodsViolatingTopologySpreadConstraint"
ref: https://github.com/kubernetes-sigs/descheduler/blob/master/examples/topology-spread-constraint.yaml
注意点
DeschedulerによってEvict対象のPodが多いことでサービスのキャパシティが足りなくなってしまったり、ダウンタイムが発生する可能性があります。
そうならないためにもPodDisruptionBudgetを設定することで最低限起動するPod数を保証できます。
PodDisruptionBudgetはDeschedulerやDeployment strategyよりも優先的に扱われます。
設定例
apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: my-app spec: minAvailable: 2 selector: matchLabels: app: my-app
まとめ
KubernetesでPodをMulti AZにスケジュールする方法、設定する上での注意点を紹介しました。